
AWS Essentials for Data Science1. Why Cloud Computing?
#aws
#python
Written by Matt Sosna on April 17, 2022
Imagine you’re a coordinator for data science meet & greets in New York. A major part of your planning involves reserving a venue to accommodate your guests. You’ve always rented venues around the city, but you wonder if it’d be better to just buy your own to avoid the hassle of searching for a free one every time.
If the venue is an analogy for a computer, then the cloud computing industry would interject with a resounding “No!” It is far cheaper, safer, and more scalable to rent computers in a data center than to buy your own, the argument for cloud computing goes. “Let us reserve a venue for you,” they’d say. “In fact, forget about venues altogether, and just focus on throwing a great party.”
 Photo by CHUTTERSNAP on Unsplash
Photo by CHUTTERSNAP on Unsplash
The concept of shared computer resources has existed since the 1960s, and the term “cloud computing” has been around since the 1990s. But it wasn’t until the 2000s that the industry began accelerating into the unstoppable behemoth of today. The global cloud computing market was an impressive $445.3 billion in 2021, for example, but it’s expected to more than double to $947.3 billion in just five years!
Why is cloud computing so ubiquitous? And how can I utilize it as a data scientist, machine learning engineer, or software engineer? There’s a lot to unpack with these questions, more than we can fit into one post. This post will therefore introduce cloud computing: what it is and why you should care. The following two posts will then cover storage and compute, the two central categories of cloud computing.
We’ll focus on Amazon Web Services (AWS), the market leader and arguably driver of the cloud revolution. But everything we’ll cover is applicable to the other major players: Google Cloud Platform (GCP), Microsoft Azure, Alibaba Cloud, and others. Let’s get started!
Table of contents
1. Why cloud computing?
- What is the cloud?
- Why is the cloud useful?
- What is the cloud (formally)?
- When is the cloud not right for me?
- What is AWS?
- Setting up
- Conclusions
2. Storage
3. Compute (coming soon)
What is the cloud?
To cut to the chase, the cloud is just a bunch of computers sitting in a bunch of data centers. A data center is a fancy, secure warehouse for storing a lot of running computers, likely located somewhere where the electricity is cheap or the climate is cold.
These computers don’t have monitors or keyboards – they’re just the hardware that performs calculations, stores and retrieves data, responds to HTTP requests, etc. We call these machines servers to distinguish them from the human-friendly laptops or desktops most people are familiar with, as they serve responses to user requests.

Racks of servers in a data center. Photos by imgix on Unsplash (left) and dlohner on Pixabay (right)
The data centers of the largest tech companies – Amazon, Meta, Google, etc. – have millions of servers stacked on top of each other in rack after rack extending as far as you can see. Any time a person uploads a cat photo to Instagram, or bookmarks a pair of shoes on Pinterest, or responds to a message on WhatsApp, they interact with a few of these servers.[1]
Why is the cloud useful?
You’re likely already familiar with the convenience of cloud storage if you’ve ever used iCloud, Dropbox, or Google Drive. You can recover your texts if you lose your phone; you can share files with links instead of massive email attachments; you can organize and search your photos by who’s in them.
But the cloud is useful beyond making your personal life smoother: it can augment your professional life, too. Not all of Amazon’s servers are busy handling searches for shoes, or determining which users to show ads for Elden Ring. Some of these servers, in fact, are available for you to rent for yourself.
The ability to rent servers, without needing to buy and then maintain them, is the cloud’s major offering. If the cloud industry had a slogan, it would be “Whatever resources you need, whenever you need them.” If servers are like water droplets in a physical cloud, then the industry prides itself on users being able to mold that cloud into whatever size and shape best fits their needs.
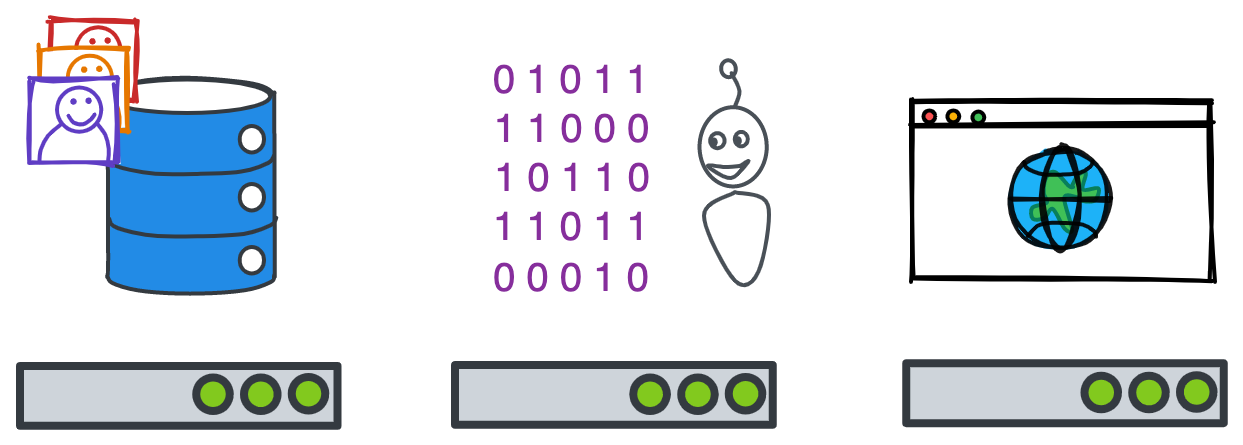
Let’s say you’re launching a dating app. You’ll need a way to store user photos, as well as a way to train recommender systems to match users. Simply rent a server optimized for storage to host the photos; another optimized for running the calculations for the ranking models; and maybe a small one for hosting the site, handling user authentication, etc.
Scale these three servers up to four, five, or more as your app’s audience grows around Valentine’s Day, and then back down to three as users’ dating lives quiet down. Ditch the calculations server entirely when you decide to start matching users randomly.
Throughout this wild ride, you only pay for what you use. You also avoid the upfront costs of purchasing the hardware yourself, and you’re off the hook if a user uploads so many photos that your storage server breaks down. Cloud providers bake in ample backups and redundacy, meaning customers can essentially forget about the exact machine(s) running their services.
Finally, I’ve been saying “servers” as though you’re renting the entire machine. But to make it even easier to leverage the cloud, customers can reserve a portion of a server, which still acts like an independent machine. This virtualization benefits both customers and cloud providers – you can reserve as little compute or storage as you want, and providers can keep servers busy (and earning money) by splitting them between multiple customers.
What is the cloud (formally)?
NIST (National Institute of Standards and Technology) provides a more formal definition of the cloud by outlining five essential characteristics:
1. On-demand self-service
Customers can choose the compute resources they need without requiring human interaction with the provider. For example, a user can click a button to reserve a server to host their website, then click another button to release the server.
2. Broad network access
These resources are available over the internet, and they can be accessed through multiple platforms. For example, a user can reserve a server from their laptop, then later check on its health from their phone.
3. Resource pooling
Cloud resources are dynamically assigned and reassigned, with the specific location of resources abstracted away from the user. For example, a user can reserve two servers and not need to know that one is server 123 in Data Center A in Virginia and the other is server 456 in Data Center B in New York.
4. Rapid elasticity
Resources can be provisioned and released to quickly match demand. For example, a user can select to automatically utilize more servers when traffic to their app increases.
5. Measured service
Resource use is precisely metered, visible, and controllable. For example, a user can see in real-time how much the servers hosting their app cost, and reconfigure their allocation as business needs change.
Let’s return to the venue reservation analogy. A “Venue AWS” service would advertise that you can automatically reserve whatever size venue you need through their website or app (#1, #2). These venues are drawn from a large set of rooms that disappear and reappear as users’ events start and stop (#3). If you suddenly get far fewer or far more attendees than you expect, or as attendees come and go, you can dynamically teleport everyone to the best-sized venue (#4) as many times as you want. Finally, you see exactly what you’re paying for and can pull the plug if you change your mind at any point (#5).
When is the cloud not right for me?
Before we move on, it’s worth mentioning the arguments against cloud computing. Despite their best efforts, cloud providers do fail occasionally, taking down their customers with them. In November 2020, for example, Adobe, iRobot, and Roku went offline for several hours due to an error in how a batch of new servers were added to an AWS data center. Similarly, cloud providers aren’t immune to data leaks, like when all of Twitch’s source code was leaked or a disgruntled employee voluntarily leaked customer info.
If you’re working in an area where user data is extremely sensitive (e.g., social security numbers) or your application absolutely cannot be interrupted (e.g., emergency response), it may therefore be necessary to invest in a system that you can fully control.
What is AWS?
AWS, or Amazon Web Services, is Amazon’s cloud offering. AWS launched in 2002 as part of Amazon’s push to have a more service-oriented architecture for their software engineers. The goal was ambitious: maximize the autonomy of teams, adopt REST APIs, standardize infrastructure, remove gatekeeping decision-makers, and continuously deploy code. Amazon determined that a distributed, scalable software architecture was needed to fulfill this ambition.
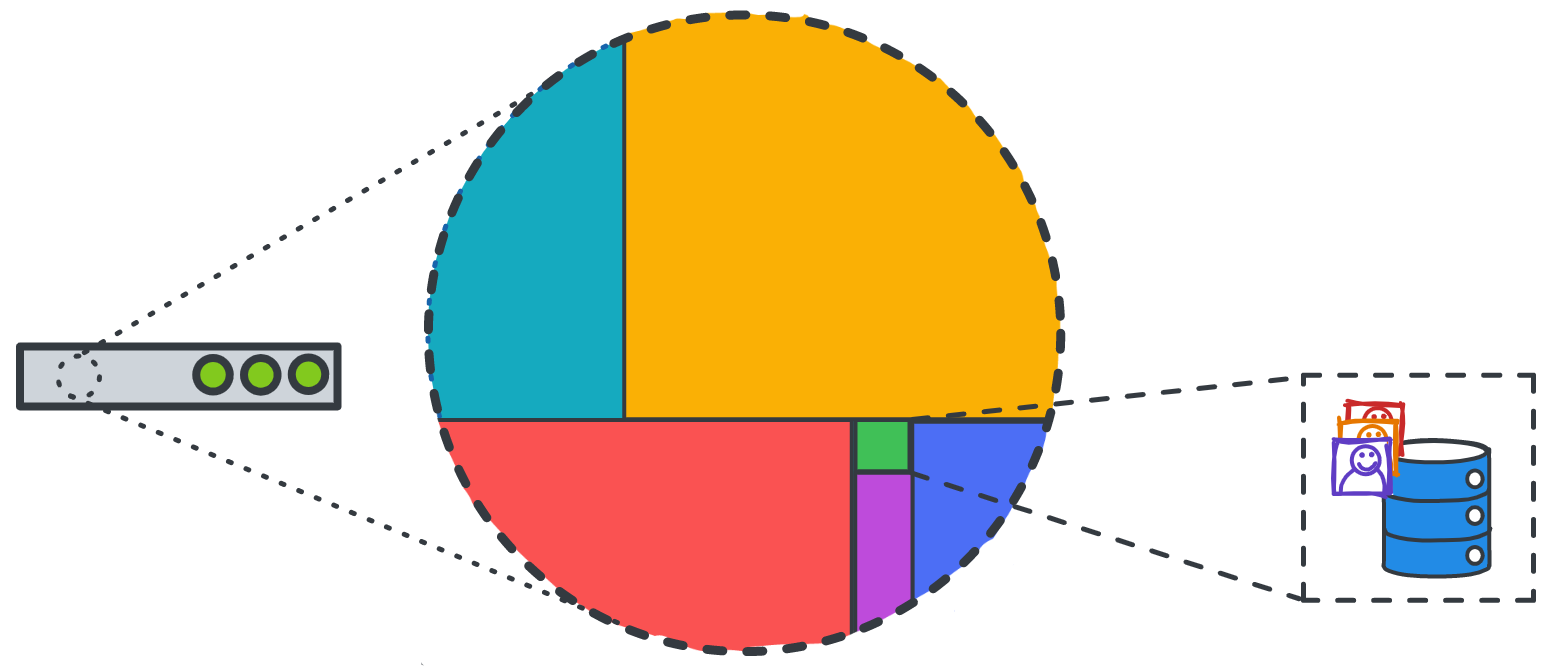
The result was so successful that Amazon turned AWS into a product for the public to utilize, too. AWS currently captures about 32% of the cloud computing market (Microsoft Azure and Google Cloud follow at 20% and 9% respectively) and offers over 200 services with varying levels of abstraction. Get down to the operating system level and optimize the foundations of the servers running your app, or just launch your app through a service that handles most of the details for you.
Setting up
Let’s create an AWS account. These posts will make more sense if you can follow along, and you’ll be able to then experiment on your own later.
We start by going the AWS website and clicking “Create an AWS Account.” AWS offers most of their services free for one year, meaning you can learn and experiment with the real thing without needing to worry about costs. (You do need to attach a credit card, though, just in case you decide to buck the gentle tutorials and start training the next AlphaGo.)

Assuming you’re not a robot (🤖), it should be pretty straightforward to follow the steps all the way through. (No trick questions yet!) Once you’ve created an account, you should see the console home with widgets like the most recent apps visited, some “Welcome to AWS” links, cost and usage, and more.
IAM (Identity and Access Management)
We made it! Should we start building an image classifier or a chatbot? How about a video game engine or satellite controller? Actually… let’s start with identity management.
It might sound anticlimactic to kick off our AWS adventure with identity management, but following security best practices is essential for successfully leveraging the cloud. Your app’s customers won’t be very sympathetic if you get hacked (especially if their data is stolen!), and an attacker can easily rack up thousands of dollars in expenses before you cancel your credit card. On a friendlier note, setting up identity management lets you easily and securely pull in new developers to your project!
When you created an AWS account, you created a root user. This is an all-powerful user for the account, one who can perform any action on any service, create and delete other user profiles, access and change payment info, and close the account. That’s a lot of power concentrated in one place. In fact, the absolute first thing AWS recommends new users do is set up multi-factor authentication (MFA) to make it impossible harder for attackers to break into the root account.
You’ll see a big red warning that the root user is unprotected if you navigate to IAM, AWS’s Identity and Access Management service. (Type “IAM” in the search bar to find it.)
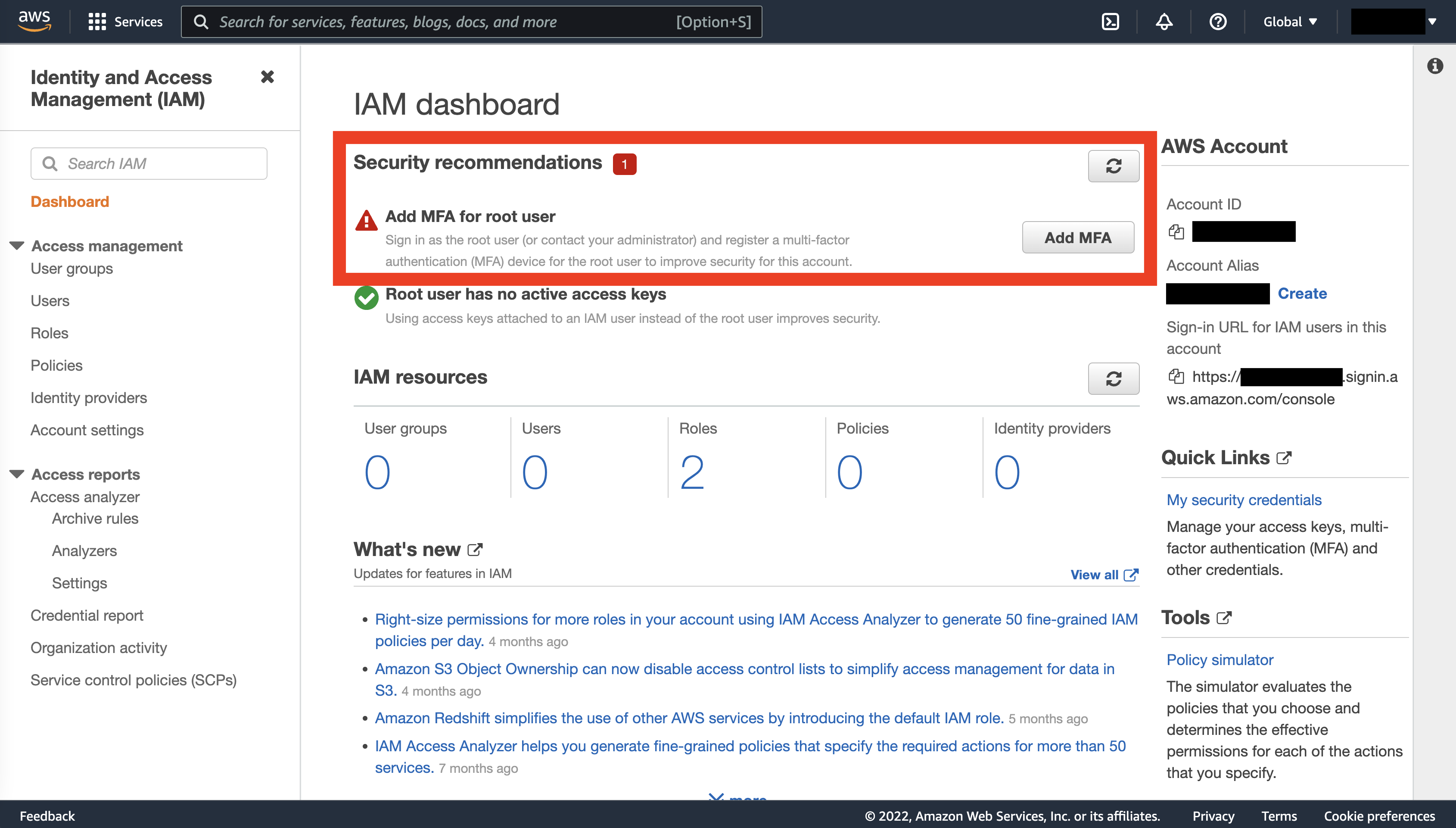
So let’s fix this vulnerability – just click on “Add MFA,” choose the method (such as an authenticator app on your phone), and then follow the provided steps. Once MFA is set up, anyone trying to log in as the root user will also need to provide additional proof that they’re really you. This additional hassle is worth it – you usually won’t be logging into the root account anyway.
Rather, you’ll usually log into a user profile with specific permissions based on your typical workflow. Your day-to-day work probably doesn’t involve updating credit card details or changing customers’ passwords, for example, so you can restrict these actions for a user (including yourself unless you log in as the root user).
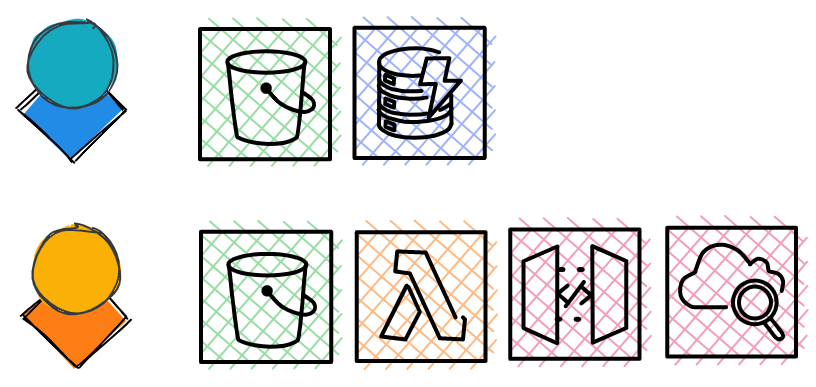
In fact, IAM profiles aren’t able to do anything unless you specifically say they can, a security concept called granting least privilege. This drastically reduces the damage a compromised account can do. The blue user below can only access S3 and DynamoDB for example, while Orange can access S3, Lambda, API Gateway, and CloudWatch. And even within a service such as S3, Blue’s access to actions or content can be configured differently from Orange’s depending on their business needs.
So let’s set up an IAM profile. We’ll first create a user group with certain permissions that automatically apply to any user within that group. This makes it easy to onboard new users, as we can just add their profile to a preconfigured group with the permissions any new user should have.
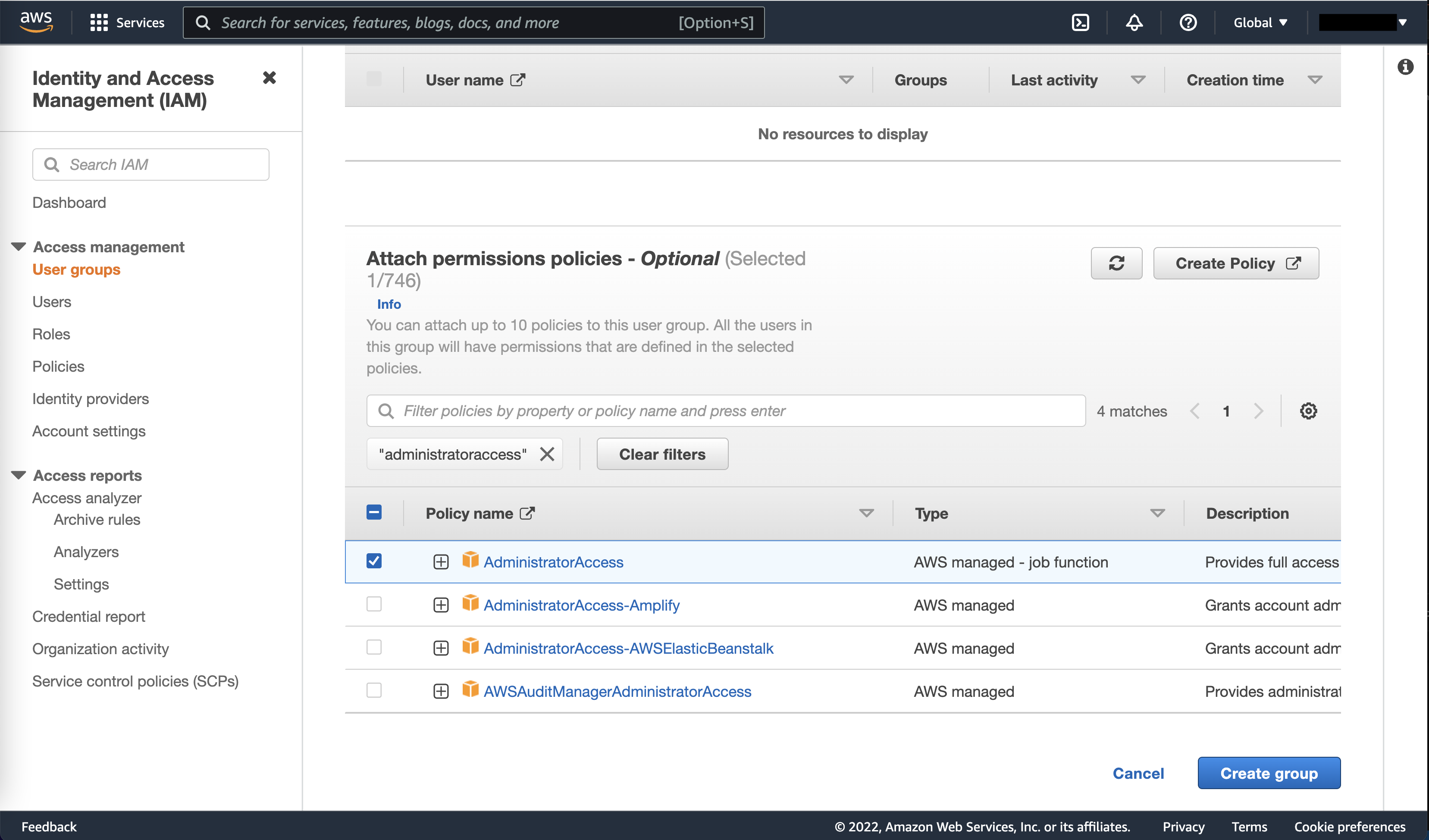
To create a group, within IAM we simply click on “User groups” on the left, then “Create group” on the right. We can name this group admins, then scroll down, search for the AdministratorAccess policy, and attach it to our group.
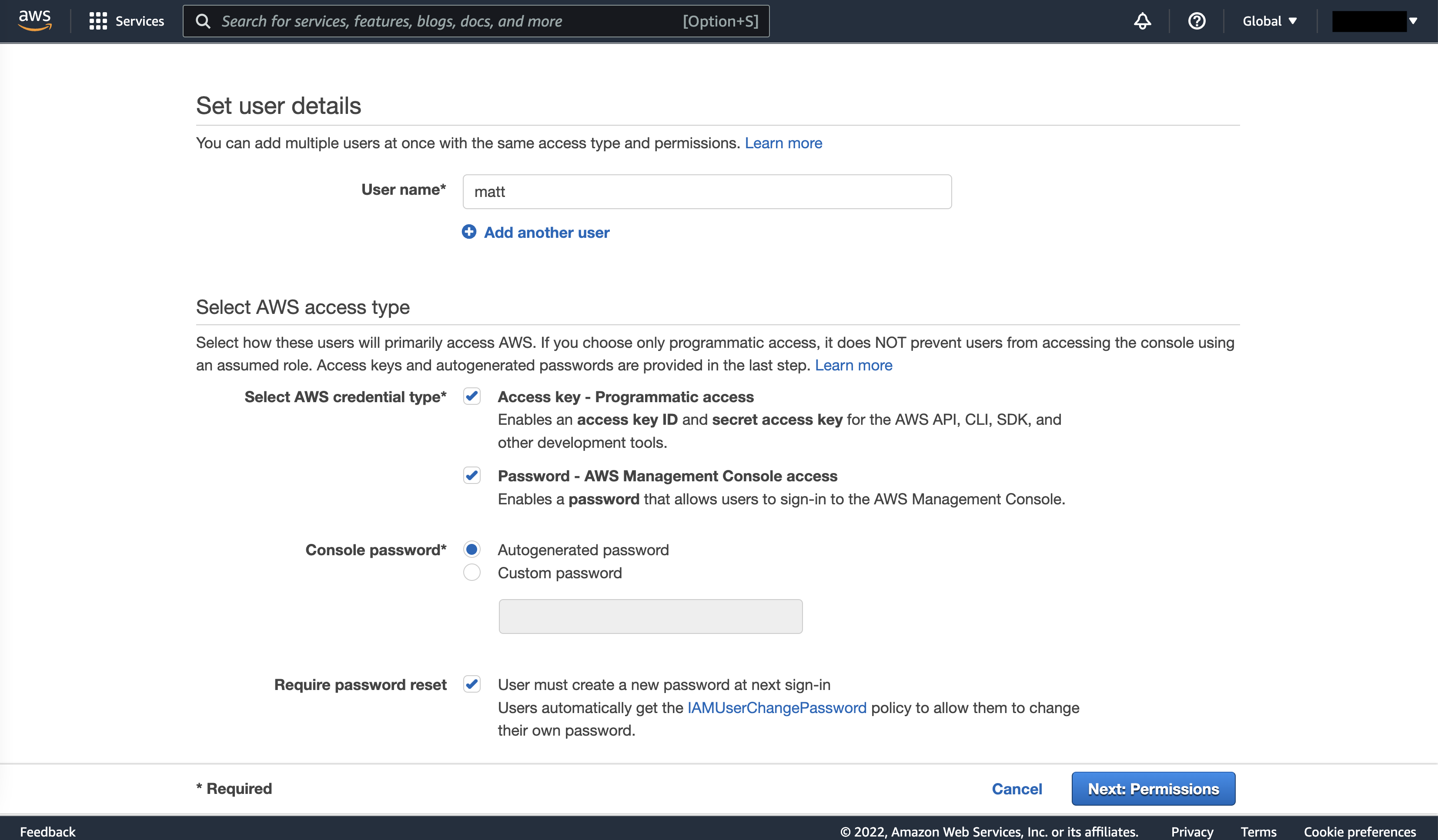
Finally, we create our user. Click on “Users” on the left, then “Add users,” and then type in a name for your account. We’ll then select both “Programmatic access” (which lets us access AWS through code) and “AWS Management Console access” (which lets us sign in as our user, rather than the root user).
We then click on “Next: Permissions” and add our user to our admins group. “Next: Tags” allows us to add tags for search (if we had dozens or hundreds of users, for example), but we can skip that for now. In the final review screen, we can confirm things look right, then hit “Create user.”
The next screen is important! The auto-generated password and secret access key (for accessing AWS from code) are only provided once. Before leaving the page, write down your access key ID, secret access key, and auto-generated password somewhere secure – the access key ID and secret access key in particular are all that’s required for anyone on the internet to access your AWS services through a Python script.
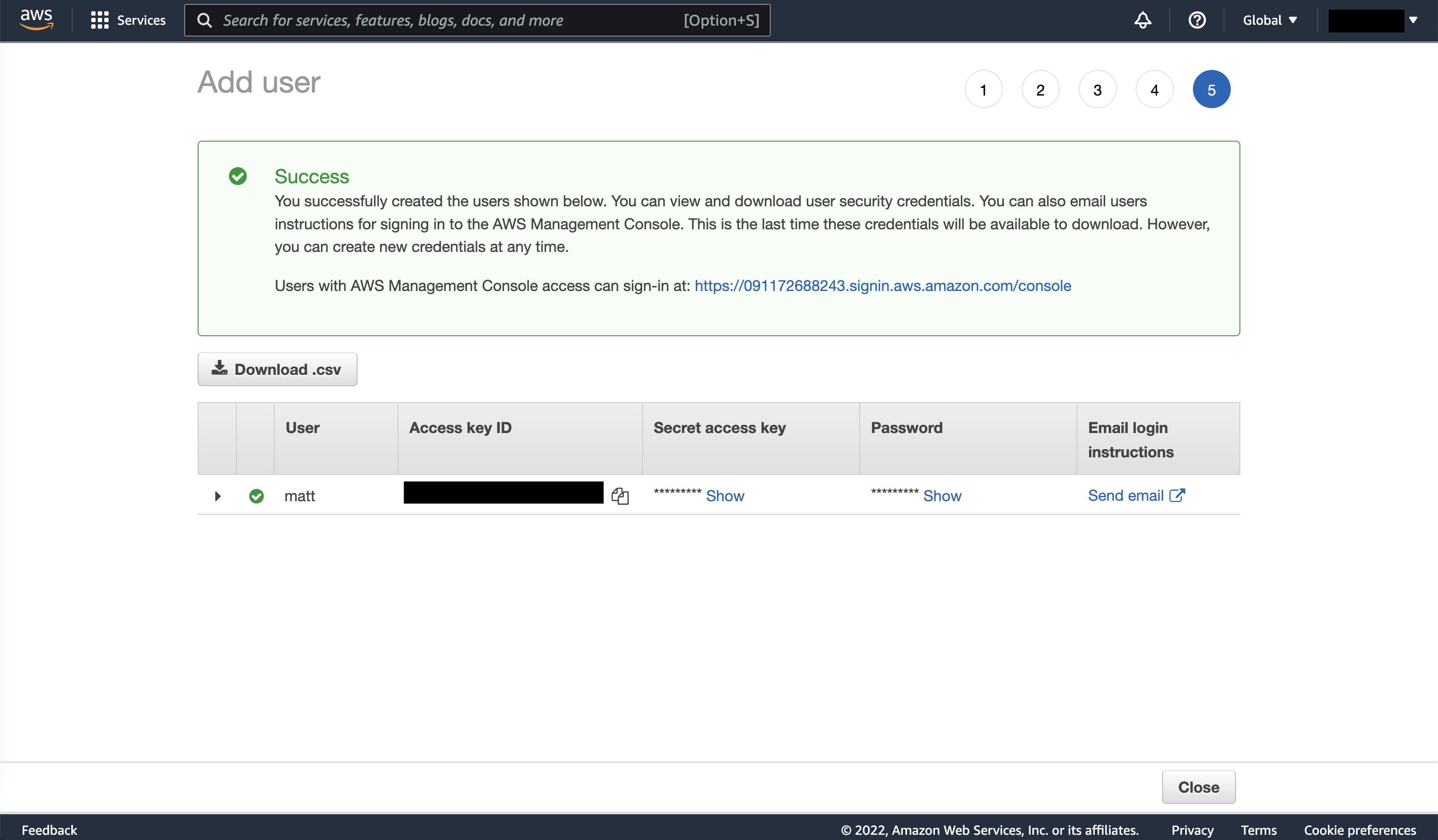
Great work! One last thing: if we’re logging in as an IAM user, we need to provide our AWS account’s 12-digit account ID. This number is hard to remember unless you’re using a password manager or have a great memory for numbers. Instead, let’s create an alias for the account (a username, basically) so we can log in with something easier to remember. Unlike our IAM profile name, this username will need to be unique across all of AWS, so you might need something more specific than matt.
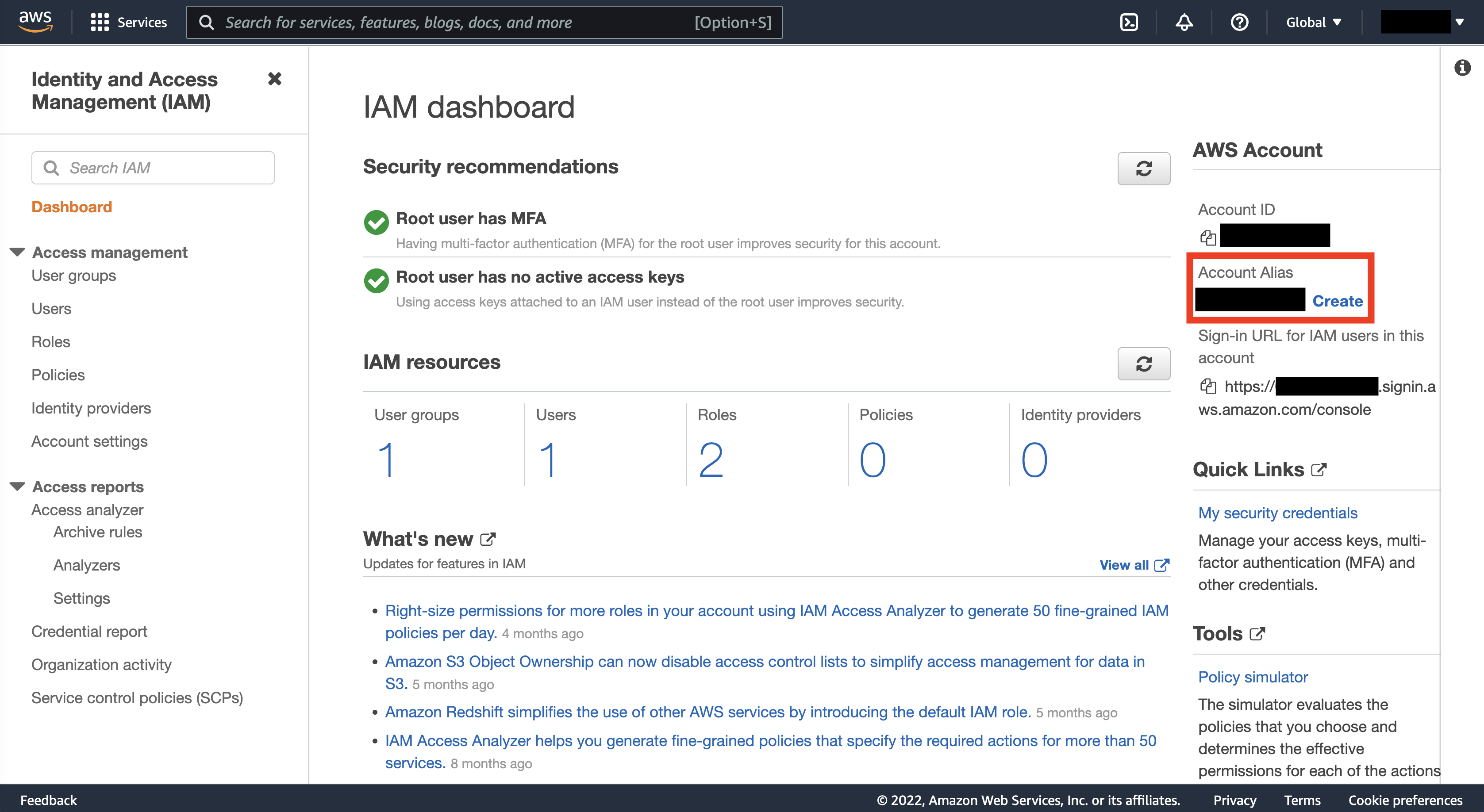
CLI (Command Line Interface)
Finally, install the AWS CLI to be able to access your AWS services from the command line. (Python users can also just type pip install awscli.) While the UI is usually sufficient for our needs, there are times where a command line interface is invaluable – uploading 10,000 CSVs into an S3 bucket can be done with a few keystrokes, for example, rather than needing to click and drag files in the UI. The CLI also sets us up to automate AWS actions – such as scaling up or down server resources – through scripts.
Once you’ve installed the CLI, you can type aws configure to input your access key ID and secret access key, as well as other details.

Congrats! 🎉 You’ve set up an AWS account, followed security best practices, and are now ready to experiment.
Conclusions
In this post, we introduced cloud computing and Amazon Web Services. We used the analogy of reserving venues to describe the main offering of the cloud: the ability to rent servers (computers) without needing to buy and then maintain them. We then covered how cloud providers allow flexible and dynamic access to servers through on-demand self-service, broad network access, resource pooling, rapid elasticity, and measured service. We then briefly covered the history of AWS and walked through setting up an account, IAM profile, and the CLI.
We’re now ready to really play with AWS and better understand its two main pillars: compute and storage. We’ll dedicate a post to each, covering the fundamentals of these offerings with plenty of fun in Python and the CLI. Hope to see you there!
Best,
Matt
Footnotes
1. What is the cloud?
Technically, your HTTP request to view Justin Bieber’s latest tweet likely doesn’t make it all the way to one of these massive data centers. Rather, you probably only make it to the nearest content delivery network (CDN) node (a.k.a. point of presence, PoP), one of thousands of smaller data centers scattered all over the world.
CDNs alleviate the load on data center databases (and the internet as a whole) by caching popular content. It’s much faster to retrieve data from a cache than from disk, meaning the server can immediately send back that Bieber tweet rather than needing to dig through trillions of tweets to find it. Indeed, Netflix is able to offer such a seamless streaming experience because they utilize massive CDNs.
But of course, there are limitations to CNDs or they’d be all we use. The hardware used for caches is expensive – 1 TB in AWS is $23 on S3 and $85 on CloudFront, for example. There’s also plenty of content we can’t store in a cache, like user data that we want locked behind a login.