
Fish schools as ensemble learning algorithms
#academia #machine-learningWritten by Matt Sosna on June 3, 2021
 Photo by jean wimmerlin on Unsplash
Photo by jean wimmerlin on Unsplash
Animal groups are greater than the sum of their parts. The individual termite wanders cluelessly while the colony builds a sturdy and well-ventilated mound. The lone stork loses its way while the flock successfully migrates. Across the spectrum of cognitive complexity, we regularly see the emergence of behaviors at the group level that the members alone aren’t capable of. How is this possible?
I spent my Ph.D. puzzling over how golden shiner fish $-$ a generally hopeless and not very intelligent creature $-$ form schools capable of elegantly evading predators. I read dozens of articles and textbooks, conducted experiments, analyzed data, and worked with theorists to try to make sense of how when it comes to fish, $1 + 1 = 3$, not $2$.
All the knowledge I gained seemed destined to become a pile of dusty facts in some corner of my brain when I left academia to enter data science. But as I started my data science education, I was surprised to see a curious parallel between decision-making in the fish I’d studied, and decision-making in ensemble learning algorithms.
This post will show you how ensembles of weak learners $-$ whether they’re fish or decision trees $-$ can together form an accurate information processor.
The machine
Let’s first cover the machine learning side, since you’re probably more familiar with algorithms than animals! Ensemble learning methods use a set of models to generate a prediction, rather than one single model. The idea is that the errors in the models’ predictions cancel out, leading to more accurate predictions overall.
In the schematic below, our ensemble is the set of gray boxes, each of which is a model. To generate a predicted value for the input, the input is sent into each model, which generates a prediction. These individual predictions are then reduced to one aggregate prediction by either averaging (for regression) or taking the majority vote (for classification).
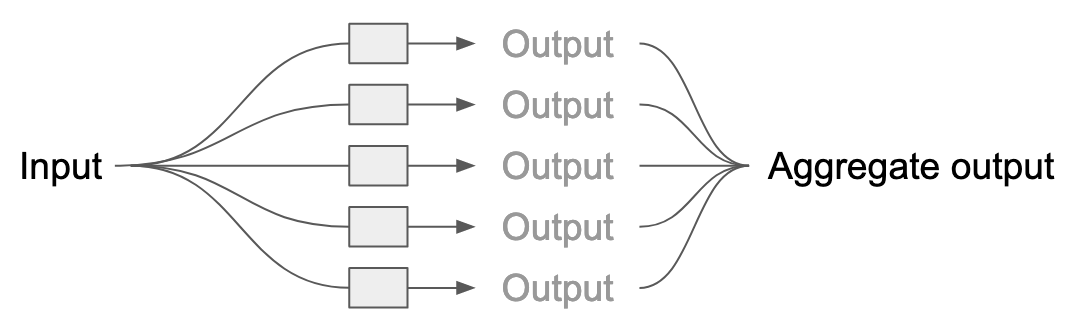
One popular ensemble method is a random forest, a model that consists of dozens or hundreds of decision trees. While there are plenty of ways to configure how the forest is assembled, the general process is that each tree is independently trained on bootstrapped observations and random subsets of the features. (If we used the same data for each tree, we’d create the same tree each time!)
The result is a collection of models, each with a slightly different understanding of the training data. This variation is crucial. Individual decision trees easily become overfit to their training data, obsessing over patterns in their sample that aren’t necessarily present in the broader world. But because the ensemble consists of many trees, these errors tend to cancel one another out when the aggregate prediction is calculated.
The theory
The enhanced accuracy of a random forest can be summarized as the wisdom of the crowds. The concept dates back to 1906 at a livestock fair in Plymouth, MA, which held a competition to guess the weight of an ox. Nearly 800 farmers gave their best estimates. Statistician Sir Francis Galton later examined the guesses and observed that while individual estimates varied widely, the mean of the estimates was more accurate than any individual guess. Galton went on to formalize his theory in his famous Vox Populi paper.

There are two key requirements for the wisdom of the crowds to work. The first is that individuals must vary in their information. If everyone has the same information, the group’s decision isn’t going to be any more accurate than an individual’s. This can even lead to less accurate decisions in general as group members become overly confident in their echo chamber.[1]
The second requirement is that individual estimates must be independent. If those 800 farmers deliberated with their neighbors before voting, the number of unique perspectives would collapse to a few hundred, maybe even only a few dozen, as people’s opinions began influencing each other. The opinions of loud personalities would weigh more than those of the quiet; rare information would be discarded in favor of common knowledge.
In a way, those farmers are like a random forest that took decades to train. Throughout their lives, each farmer learned how to map various features of an ox $-$ the size of its horns, the height at the shoulder $-$ to a weight. At the fair, each farmer took a new datapoint and independently cast an estimate. Galton then finished the analogy by aggregating their responses into a final prediction.
The fish
While the wisdom of the crowds can explain the cattle fair, the story gets more nuanced for our shiners. A random forest isn’t quite the right algorithm to describe schools of fish for one major reason: the information a fish has about its environment is strongly correlated with its neighbors.
Consider the image below of a school of 150 golden shiners. The field of view of each shiner has been approximated using a ray-casting algorithm, and only the rays that actually leave the group are colored white.
 Image from the supplementary info for Rosenthal et al. 2015.
Image from the supplementary info for Rosenthal et al. 2015.
The first thing that jumps out is that the inside of the school is a dead zone of information about the outside world $-$ these fish only see other fish. The second thing to notice is that even for shiners that do see the outside, individuals near one another are receiving essentially identical information about their surroundings.
How can a group like this possibly make informed decisions about whether to turn left or right, or explore for food or hide from a predator, when there’s only a tiny handful of independent datapoints about the outside world? (And then coordinate those dozens of group members without a leader!) Yet somehow shiner schools efficiently find shelter and modulate responsiveness to risk, even though individuals’ information is spatially autocorrelated, which prevents the wisdom of the crowds.
Unfortunately, there aren’t easy answers to these questions! The field of collective behavior is hard at work trying to understand how simple local interactions give rise to complex group-level behaviors. But there are two classes of machine learning algorithms that I think can explain some aspects of how fish schools do what they do.
The first is boosting ensemble learning. A random forest uses bagging, which involves training each model independently in parallel. Methods like AdaBoost and XGBoost, on the other hand, train models sequentially, with later models learning from the errors of earlier models. Schooling fish rapidly learn to identify predators from the mistakes of others, and fish that understand environmental cues usually end up driving the direction of group movement.
The second possibility is that fish schools act as a massive neural network. (From biological neurons to artificial neural networks to fish schools… we’ve come full circle!) When it comes to avoiding predation, many fish species perform startle responses, a super-fast, reflexive burst of swimming away from an alarming stimulus.[2] These responses are contagious, often leading to cascades of startles that move faster than attacking predators.
 A startle cascade. Image from Rosenthal et al. 2015.
A startle cascade. Image from Rosenthal et al. 2015.
The interesting wrinkle here is that the outputs of group members (i.e. whether or not they startle) serve as the inputs to neighboring fish for whether they should startle. Especially for fish deep in the group, with little personal information to verify whether a wave is a false alarm or oncoming predator, responding appropriately to these social cues can mean life or death.
We typically think of artificial neural networks as modeled off of biological neural networks, but in a way, the entire school acts a set of neurons when processing information about risk in its environment. But what’s even more fascinating is that these neurons can change the structure of their network to change how information is processed.
In one of my papers, my colleagues and I showed that shiners modulate their responsiveness to threats by changing the spacing between individuals rather than the internal calculations for whether or not to respond to a neighboring startle. This means the group structure itself, rather than individuals, controls whether random startles spiral into full cascades or die out as false alarms.
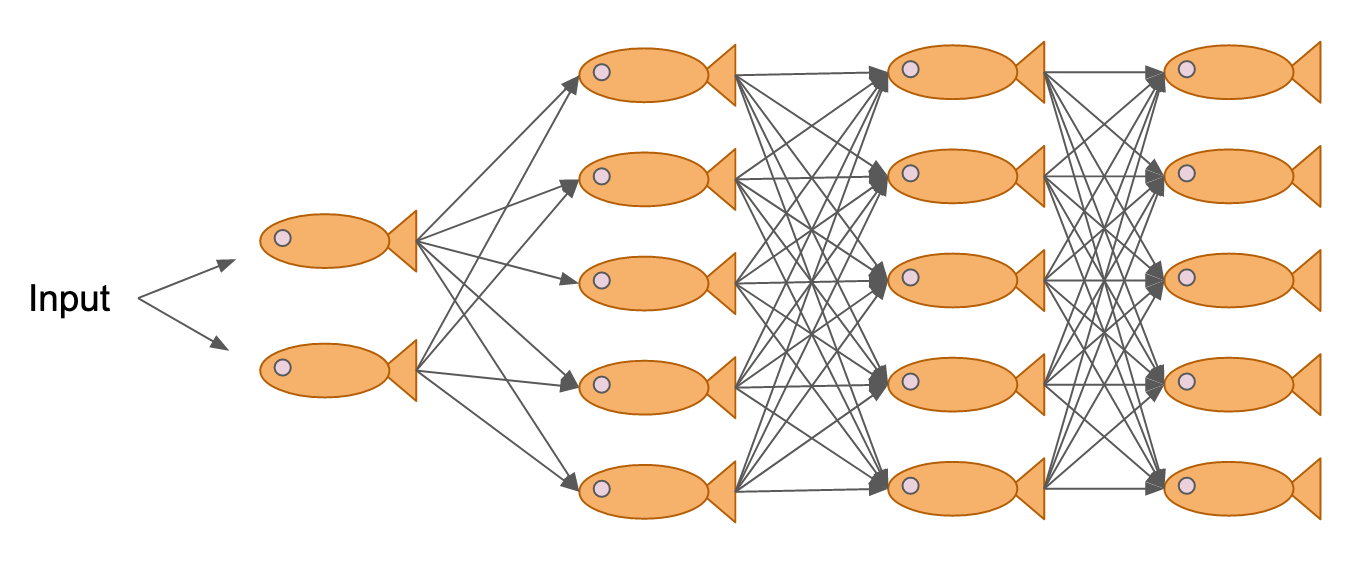 A neural network of neural networks decides where to eat.
A neural network of neural networks decides where to eat.
Conclusions
How can animal groups perform behaviors the individuals aren’t capable of? This is the central question the field of collective behavior chews on all day, bringing together biology, psychology, physics, and computer science to try to answer. In this post we covered a simple example of collective intelligence, where independent estimates of an ox’s weight led to a more accurate estimate overall. We then skimmed the surface of collective computation in fish schools, whose amorphous structure changes constantly as it processes information about its surroundings.
Interested in learning more? Check out how baboons make movement decisions democratically, innovative behavior is retained across generations in wild birds, or how slime molds recreated the Tokyo subway map by optimizing resource allocation. And be sure to check out the Collective Behavior department at the Max Planck Institute for Animal Behavior for the latest cool collective behavior research.
Best,
Matt
Footnotes
1. The theory
If you never encounter a different worldview online, or you only ever see it framed as belonging to an idiot, then you’re likely in an echo chamber. A lot of this is inevitable as social networks tend to self-segregate, meaning it’s on you to seek out the diverse viewpoints necessary for a more objective worldview.
2. The fish
To get super in the weeds, there may actually be multiple neural pathways for startles, some with finer motor control. Shiners, at least, can startle with varying intensity. But when quantifying the spread of information in a group, it’s a fine approximation to binarize startles into “yes, this fish startled” vs. “no, they didn’t.”