
Building a full-stack spam catching app 1. Context
#machine-learning
#projects
#python
Written by Matt Sosna on March 11, 2021

SpamCatch is a fun side project I did to bring together natural language processing, Flask, and the front-end. Classifying spam text messages is a classic machine learning problem, but I’d never seen people test their classifier on raw strings of text. I’d also never seen a spam classifier hooked up to a nice user interface, where people could use the classifier without needing to know Python or Git.
There’s a lot to cover, so I’ll split this into three posts. This post will set the stage for what spam is and how we can build a model to automatically identify it. The next post will build out the backend for our app $-$ the actual spam classifier and the Flask architecture for interacting with the app. In the third post, we’ll build an interface using HTML, CSS, and JavaScript so you don’t need to write code to use the classifier, and we’ll deploy the app to Heroku so anyone on the internet can use our app.
Make sure to check out the actual app! (If it takes a minute to load, that’s because the dyno went to sleep. The free plan only gets you so far!) You can also view the source code here.
Building a full-stack spam classifier
1. Context
Spam
Spam messages are at best a nuisance and at worst dangerous. While malicious spam can be carefully tailored to the recipient to sound credible, the vast majority of spam out there is easily identifiable crap. You usually don’t need to even read the entire message to identify it as spam $-$ there’s a sense of urgency, money needed or offered, a sketchy link to click.
If spam is so predictable, let’s just write some code to automatically distinguish it from normal messages (also called “ham”) and toss it in the trash. Our first guess might be to write a bunch of rules, a series of if statements that get triggered when our classifier sees certain words in the message. Accepting the risk of losing out on a once in a lifetime, all-expenses-paid vacation, I could configure my classifier to automatically delete any message with the word free in it.
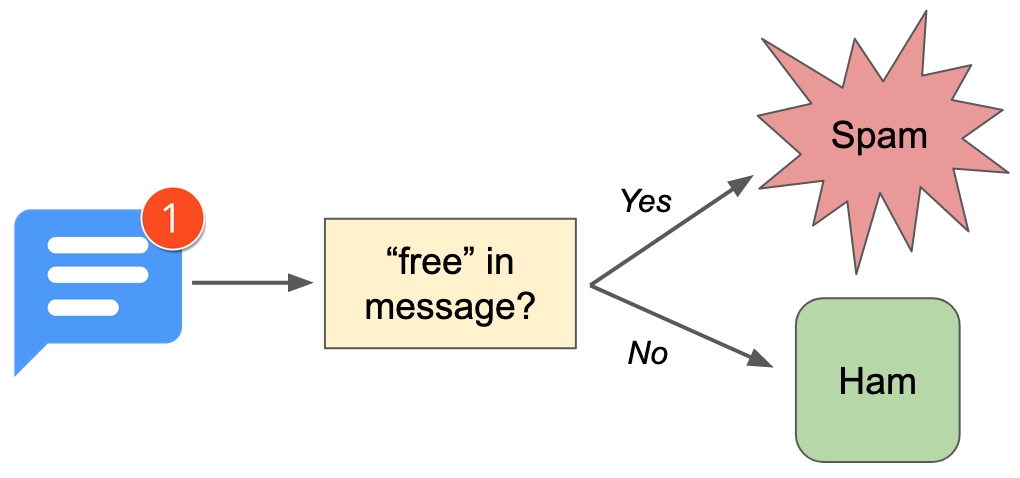
But that’s not quite right… yes, the word free pops up a lot in spam, but it also appears in normal speech all the time, too. (“Hey, are you free tonight?”, for example.) We need more rules… lots more rules.
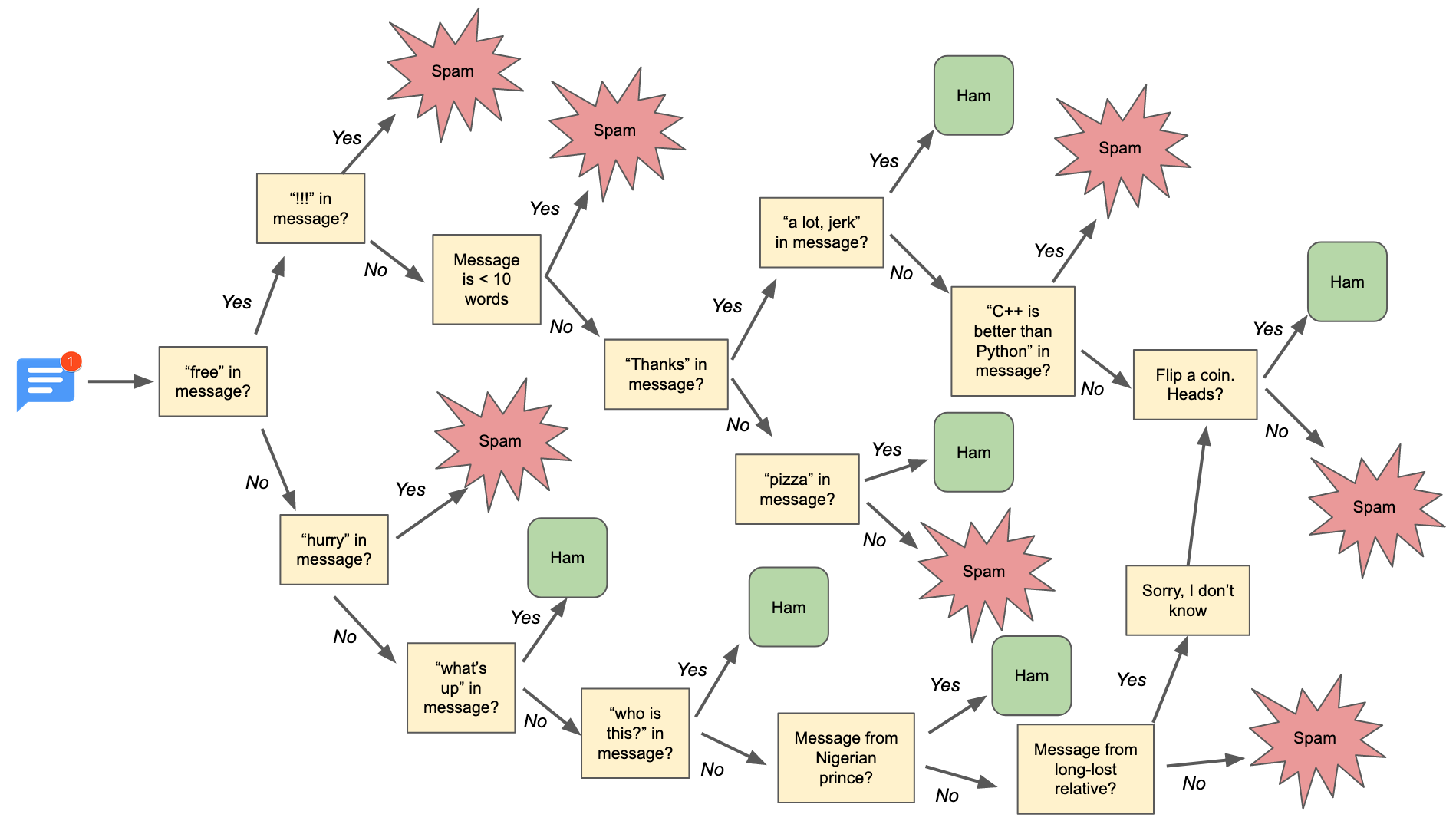
Our classifier is much more complicated and barely more accurate. In fact, it would take hundreds of hours of manually writing such a decision tree to make our classifier actually worthwhile. We’d need hundreds or thousands of if statements to be able to distinguish more subtle spam messages. We’d want the if statement logic to be informed by research on how frequently certain words appear in spam versus ham. Finally, we’d probably want our branches to increase or decrease a probability of spam rather than needing to hard-code “spam” vs. “ham” outcomes into certain branch trajectories. But most challenging of all… we’d need to write all of this ourselves!
Just kidding. But that link does point us to a tempting alternative $-$ the field of NLP, or natural language processing. NLP is a subfield of artificial intelligence that uses computational techniques to understand human language. In essence, NLP converts words to numbers so we can do math on them. With NLP, we can reinterpret our messages as vectors of numbers, then train a machine learning classifier to identify patterns in the vectors that distinguish spam from normal messages.
Finally, we need some data. We could sort through our own spam messages and text all our friends for theirs… but that’s a lot of work. (Our strange requests might also end up in their own spam!) Instead, let’s use the spam message dataset from Kaggle, a classic dataset for NLP classification problems.
Strings to vectors
We first need to decide what kind of vector to turn each text message into. The simplest approach would be to create a bag of words from our documents (a more general term for our text samples). In a bag of words approach, we first identify the vocabulary of unique words in our set of documents, then create a vector of word frequencies for each document. If our training set consisted of the three documents below, for example, our vocabulary would be the, cat, sits, is, and black, and we could categorize each document by how frequently each word appears.
| Document | the | cat | sits | is | black |
|---|---|---|---|---|---|
| the cat sits | 1 | 1 | 1 | 0 | 0 |
| the cat is black | 1 | 1 | 0 | 1 | 1 |
| the black cat sits | 1 | 1 | 1 | 0 | 1 |
Inspired by Victor Zhou
But these “term frequency” vectors created by a bag of words aren’t that informative. Yes, they tell us how many times the word cat appears in a document, for example. But knowing that cat appears once in “the cat sits” becomes meaningless when you realize cat appears once in every document! In fact, unless we looked at all the other documents, we wouldn’t know whether cat appearing 100 or 1,000 times in a document is informative at all.[1]
It’s therefore better to weight our term frequency vectors by how frequently the terms occur across all documents. If every document says the word cat 100 times, it’s no big deal $-$ but if your document is the only one to mention cat, that’s incredibly informative! These weighted vectors are called term frequency - inverse document frequency (TF-IDF) vectors.
Finally, we’ll also want to remove stop words and perform lemmatization. Stop words are words like the, and, if, etc. whose main purpose is linguistic logic. Stop words don’t contain information about the content of the document, so they just make it harder for a model to discriminate between documents.[2] Similarly, the words eating, eats, and ate look like entirely different terms to an NLP model when they’re really just different ways of saying eat. Lemmatization is the process of stripping that linguistic layer off the root of each word.
When we remove stop words, perform lemmatization, and weight the above term frequency vectors by their document frequencies, we get these TF-IDF vectors:
| Document | black | cat | sit |
|---|---|---|---|
| the cat sits | 0.000 | 0.613 | 0.790 |
| the cat is black | 0.790 | 0.613 | 0.000 |
| the black cat sits | 0.620 | 0.481 | 0.620 |
The values are now a lot less intuitive for us, but they’re much more informative to an algorithm trying to discern between the documents.
Why random forest?
The TF-IDF vectors in the table above are only three elements long, since our slimmed-down vocabulary only consists of the words black, cat, and sit. There are also few zeros in the vectors $-$ all vectors have at least 2/3 of all words in the vocabulary.
To actually catch spam, we’ll want a vocabulary with thousands of words. TF-IDF vectors trained on this vocabulary will mostly consist of zeros, since not every document will include every word in our training set. Such high-dimensional and sparse (mostly-zero) vectors are difficult for classical statistics approaches.[3] We also care less about understanding exactly how our model catches spam $-$ we just want the most accurate predictor possible.
We’ll therefore want to use machine learning. My first choice is usually a random forest algorithm unless I need something more specialized. A random forest consists of a series of decision trees fit to bootstrapped subsets of your data. Individual trees tend to become overfit to their training data, but these errors average out across all trees, resulting in an ensemble that can generate surprisingly accurate predictions.[4]
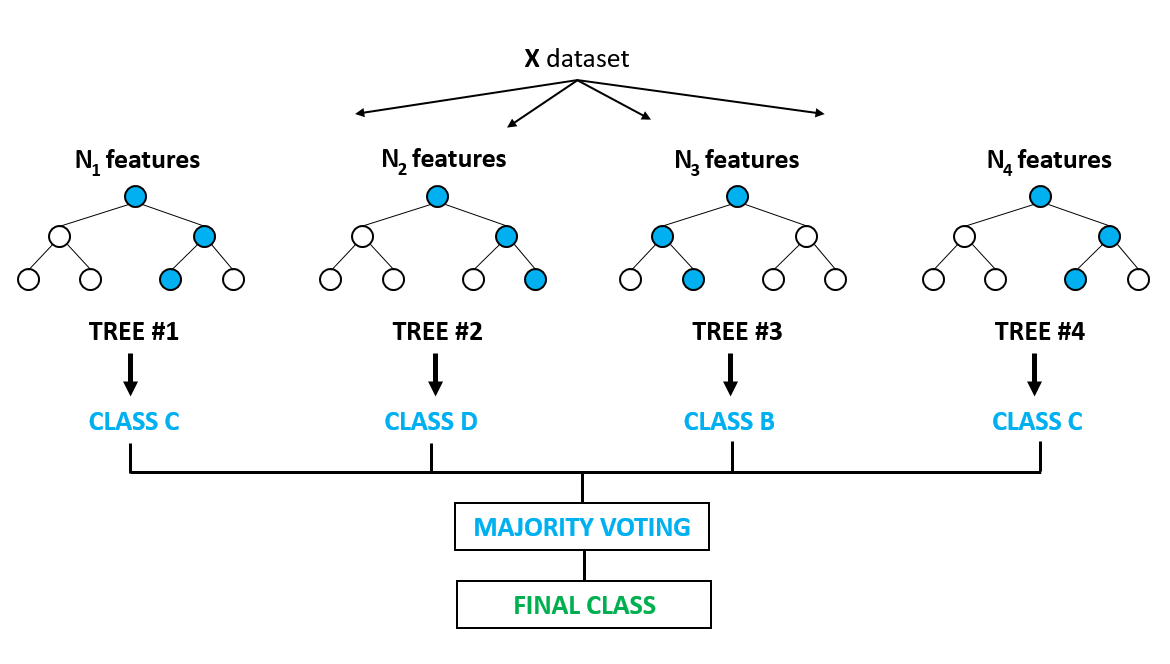 Source: Kaggle
Source: Kaggle
What is Flask?
One more concept before we start building our app. It’s one thing to have an amazing model tucked away in a Jupyter notebook hidden in your computer, and entirely another to have that model accessible to the world. Flask is a Python library that lets you make code accessible outside your current Python environment. With Flask, you can create a server with functions at API endpoints.
These endpoints are the interface between your code and the outside world. They let you access your Python code while you’re in another Python script… or even when you’re not using Python, but your browser. We’ll build our app so we actually interact with our Python spam prediction model on an HTML page, using JavaScript to communicate between the user and our model. Our app will mimic the flow chart below, minus the database.[5]
 Source: ServiceObjects
Source: ServiceObjects
Conclusions
This post went through the theory for our spam-catching model, setting the stage for what spam is and how we can identify it. In the next post, we’ll actually build out our spam classifier, as well as build a micro web service with Flask. In the final post we’ll build some HTML pages, style them with CSS, and then use JavaScript to communicate between the page and Flask. See you there!
Best,
Matt
Footnotes
1. Strings to vectors
Some would consider the word cat appearing 100 times in a document to be… catastrophic.
2. Strings to vectors
While grammar like stop words and punctuation distract our model from the content of a document, they do still hold valuable information a more advanced model will want to incorporate. Consider these two sentences:
“Most of the time, travelers worry about their luggage.”
“Most of the time travelers worry about their luggage.”
That comma is pretty important for knowing what kind of travelers we’re talking about!
3. Why random forest?
This article from Philosophical Transactions of the Royal Society A: Mathematical, Physical, and Engineering Sciences goes into great detail on approaches for dealing with sparse vectors. One of the issues they mention is that when the number of features is greater than the number of samples, $X^TX$ becomes singular and cannot be used to estimate model parameters.
4. Why random forest?
The fact that ensemble methods generate predictions more accurate than individual models reminds me a lot of collective animal behavior, which my Ph.D. was on. I’ll need to write a blog post nerding out on the comparisons sometime.
5. What is Flask?
The Flask SQLAlchemy library lets you set up and integrate a database into your Flask application. We could do this, for example, if we wanted to save every query users submit to our app. But be wary of SQL injection attacks!