
Tag: statistics
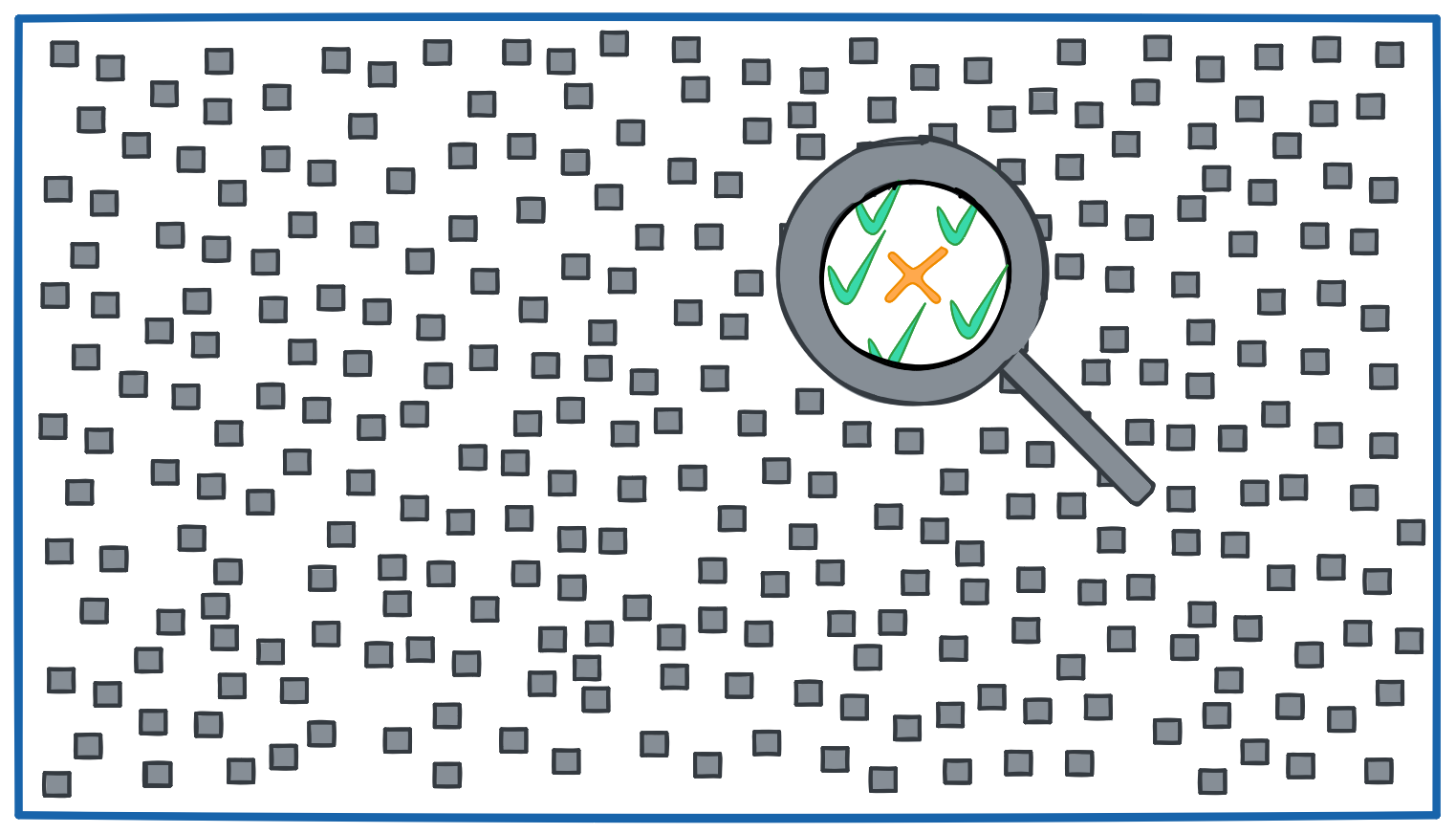
A business lens on precision and recall
December 20, 2023#machine-learning #statistics
A deep dive on ARIMA models
August 11, 2021#python #statistics
Predicting the future has forever been a universal challenge, from decisions like whether to plant crops now or next week, marry someone or remain single, sell a stock or hold, or go to college or play music full time. We will never be able to perfectly predict the future[1], but we can use tools from the statistical field of forecasting to better understand what lies ahead.
How to enter data science 2. The statistics
December 5, 2020#careers #data-science #statistics
In the last post, we defined the key elements of data science as 1) deriving insights from data and 2) communicating those insights to others. Despite the huge diversity in how these elements are expressed in actual data scientist roles, there is a core skill set that will serve you well no matter where you go. The remaining posts in this series will define and explore these skills in detail.
Visualizing the danger of multiple t-test comparisons
May 13, 2018#projects #r #statistics
It’s often tempting to make multiple t-test comparisons when running analyses with multiple groups. If you have three groups, this logic would look like “I’ll run a t-test to see if Group A is significantly different from Group B, then another to check if Group A is significantly different from Group C, then one more for whether Group B is different from Group C.” This logic, while seemingly intuitive, is seriously flawed. I’ll use an R function I wrote, false_pos, to help visualize why multiple t-tests can lead to highly inflated false positive rates.
Linear regression via gradient descent
April 22, 2018#machine-learning #projects #r #statistics
After hearing so much about Andrew Ng’s famed Machine Learning Coursera course, I started taking the course and loved it. (His demeanor can make any topic sound reassuringly simple!) Early in the course, Ng covers linear regression via gradient descent. In other words, given a series of points, how can we find the line that best represents those points? And to take it a step further, how can we do that with machine learning?